
Large Language Models (LLM) like GPT, BERT, LLaMA are already solving many use cases for business but still there are many use cases where directly using LLM won’t work. For example if I ask LLM “Tell me the leave policy of my organization“, probably it will start hallucinations because it was trained on data available on the internet but not on my organization’s proprietary data.
So to solve this problem we need to have a Retrieval-Augmented Generation (RAG) process to optimize output of LLM using relevant data for queries on which LLM was not trained.
Overview
Building a RAG system is like asking LLM “Tell me the leave policy of my organization“ based on some of the documents. Technically it is, providing some context to LLM to answer my question.
To provide the context to LLM we need few building blocks to solve below problems
- Can we provide entire document as context to LLM, No all LLM have maximum allowed context size so we need to divide document in smaller chunks
- Which chunks to provide as context so we will need to do comparison of chunks and query, need to have embedding for chunk
- How to store these embeddings or vectors for efficient similarity search and retrieval
- How to connect everything to get the answer for any query
Let’s discuss all four building blocks: chunking, embedding, indexing and retrieval.
Ingestion

Chunking
A proprietary data can have vast variety with so many different writing styles, for example some hr documents in pdf format, design documents in word format, powerpoint presentations, video files, README, html and list goes on.
So having a good chunking system is very essential to process different kinds of documents, converting them to common format and creating meaningful chunks from documents where chunk size and chunk overlap size are very important parameters.
Embedding
Creating embedding is to generate vectors for chunks which will have some semantic meaning. Let’s say we have three chunks and their embeddings as below
| chunk | embedding |
| Apple is a fruit | [0.2, 0.3, …………………0.9] |
| I really like orange juice | [0.2, 0.3, …………………0.6] |
| I need to go for my car wash | [0.9, 0.1, …………………0.5] |
So the distance between the embedding vector of chunk 1 and chunk 2 will be small and the distance between the embedding vector for chunk 2 and chunk 3 will be large.
Indexing
Next we need to create a database for all this information. We have many vector databases to support all these kinds of applications like chroma, Weaviate.
These databases supports many types of search and matching algorithms to get best matching chunks to provide context to LLM, few search algorithm can be
- Dense search – Where it search based on distance between dense vectors or embeddings
- Sparse search – It is like keyword search, where it uses technique similar to bag of words for vector representation and then find the similar vector on distance
- Hybrid- Where it combines both mechanisms.
Retrieval
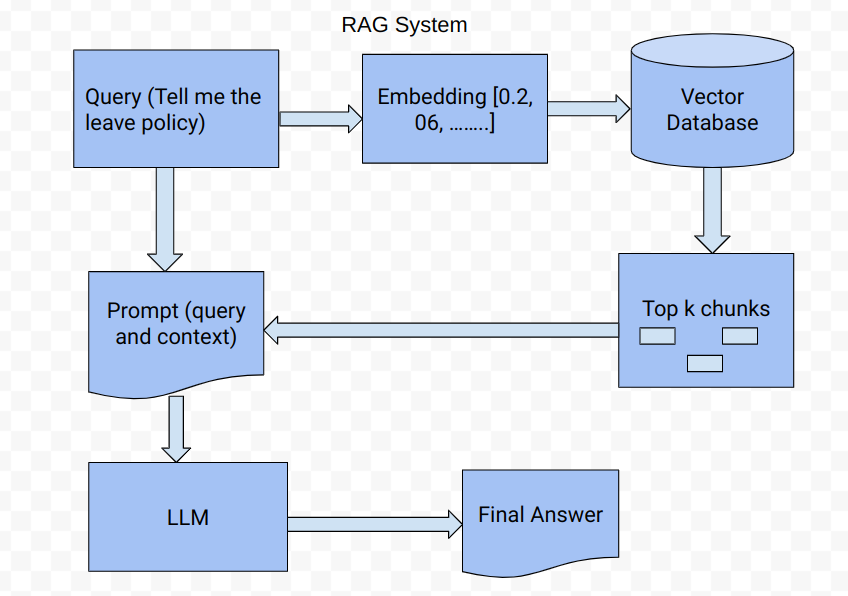
Retrieval is where we combine all things together to get final answer from LLM, which will have below high level steps:
- Get query from user
- Create embedding of query
- Get top K chunks from vector database based on query
- Create prompt with retrieved chunks and query
- Pass prompt to LLM
- Get final answer
Conclusion
If you want a LLM to answer questions based on your proprietary data implement a RAG system with appropriate technology stack for each building block.
Keep tuning to know how to build RAG and the required technology stack!


